今天我們要來用python的sklearn套件來實作KNN。第一步我們一樣先老找我們的老朋友iris資料集,同樣將特徵(feature)設為x、標籤(label)設為y。
from sklearn import datasets
import pandas as pd
data = datasets.load_iris()
x = data.data[:, [0, 1]]
y = data.target
下一步就是將資料切分成訓練集以及測試集。可以直接使用sklearn裡面的train_test_split函式,這邊筆者設定的訓練集與測試集的比例為7:3。
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 42)
接著就可以來建構模型囉!我們一樣使用sklearn的KNeighborsClassfier建構模型,筆者這邊設定的k值為3,讀者們可以自己調整成不同的數字,看看結果會有怎樣的變化喔。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(x_train, y_train)
完成後簡單的來看看準確度,可以看到對於訓練集的準確度是85.71%左右、對於測試集是75.76%左右、對整體資料是82.67%左右。
print(f"Training Set: {knn.score(x_train, y_train)}")
print(f"Testing Set: {knn.score(x_test, y_test)}")
print(f"All: {knn.score(x, y)}")

最後,我們可以利用matplotlib.pyplot函式庫來對我們的結果產生圖像化的數據,這樣可以簡單、清楚的看到成果。這邊先寫一個簡單的函式方便後面的繪圖。
import matplotlib.pyplot as plt
def plot_data(origin, data, title):
for i, d in enumerate(data):
if (d == 0):
plt.plot(origin[i][0], origin[i][1], "ro")
elif (d == 1):
plt.plot(origin[i][0], origin[i][1], "go")
else:
plt.plot(origin[i][0], origin[i][1], "bo")
plt.title(title)
plt.show()
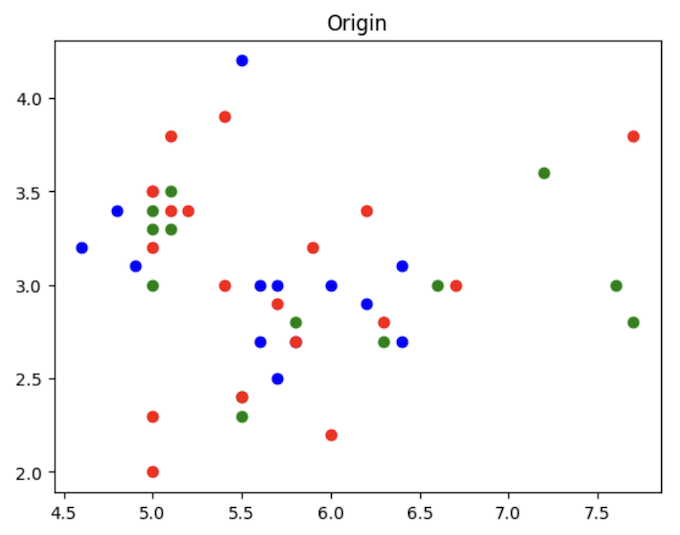
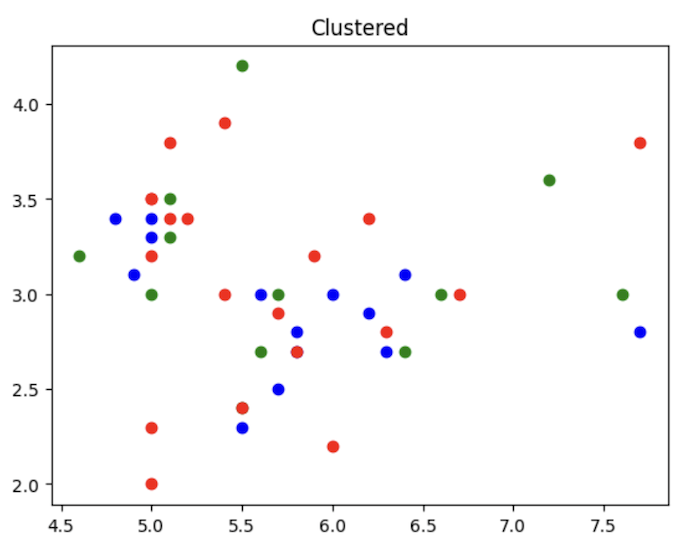
以下就是我們原先的數據以及完成分類後的數據,讀者們可以試試看調整k值後,觀察結果是不是會有不同呢!
import matplotlib.pyplot as plt
predictions = knn.predict(x_test)
plot_data(x_train, y_test, "Origin")
plot_data(x_train, predictions, "Clustered")


 iThome鐵人賽
iThome鐵人賽